ボットトラフィックについて理解する
ボットトラフィックとは、あなたのリンクをクリックする非人間的なアクセスのことです。これは懸念事項に思えるかもしれませんが、ほとんどのボットトラフィックは正当であり、インターネット上で重要な機能を果たしています。
ボットはなぜリンクをクリックするのか?
ボットがリンクをクリックするには、いくつかの正当な理由があります:
- リンクプレビュー — FacebookやX、LinkedInなどのソーシャルプラットフォームがあなたのリンクを取得してプレビューカードを生成します
- スパム検出 — メールプロバイダーやソーシャルネットワークはユーザーを悪意のあるコンテンツから保護するためにリンクをチェックします
- 検索インデックス — Googleなどのサーチエンジンがリンクをクロールしてコンテンツをインデックスします
- セキュリティスキャン — アンチウイルスとファイアウォールサービスがリンク先を検証します
Linklyがボットを識別する方法
Linklyは2つの方法を使用してボットトラフィックを検出します:
1. ユーザーエージェント検出
多くのボットはユーザーエージェント文字列を通じて自らを識別します。例えば、Googlebot、Facebookbot、Xbotはすべて自らを通知します。検出されたボットの完全なリストをご覧ください。
2. ISP検出
一部のボットは自らを識別しませんが、リクエストがAWSやGoogle Cloud、DigitalOceanなどのクラウドホスティングプロバイダーから発生しているかどうかをチェックすることで検出できます。データセンターからのトラフィックはほぼ常に自動化されています。
ソーシャルメディアクローラーの処理
Linklyは、オプションとしてFacebook、X、LinkedIn、Google、YouTubeのソーシャルメディアクローラーをあなたの分析から除外できます。有効にした場合:
- それらは分析に記録されません
- あなたのクリック制限にカウントされません
- ボットブロックが有効な場合でも常に許可されます
- カスタムソーシャルプレビューを生成することができます
これにより、ソーシャル共有がシームレスに機能し続けながら、分析が人間訪問者に焦点を当てます。
自動的に無視されるユーザーエージェント
Linklyは自動的に特定の既知のボットユーザーエージェントからのトラフィックを無視します。これらのリクエストは通常通りリダイレクトされますが、分析に記録されずクリック制限に対してカウントされません:
- Bytespider — ByteDanceのウェブクローラー
- python-requests — 自動化されたスクリプトで一般的に使用されるPython HTTPライブラリ
- curl — コマンドラインHTTPツール
このフィルタリングはすべてのリンクに対して自動的に行われ、設定は不要です。
ボットトラフィックは悪いのか?
ほとんどの場合、いいえです。ボットの大多数は有用な機能を実行する「良いボット」です。
しかし、ボットトラフィックは以下の場合に問題になる可能性があります:
- クリック数を増加させる — 実際のエンゲージメントを測定するのが難しくなります
- コンバージョン率を歪める — ボットは決してコンバージョンしないため、ボットトラフィックが多いとコンバージョン率が低く見えます
- クリック制限を消費する — ただし、ソーシャルメディアクローラーは制限から除外できます
広告プラットフォームからの無効なトラフィックについては、TikTok無効トラフィックに関する記事をご覧ください。
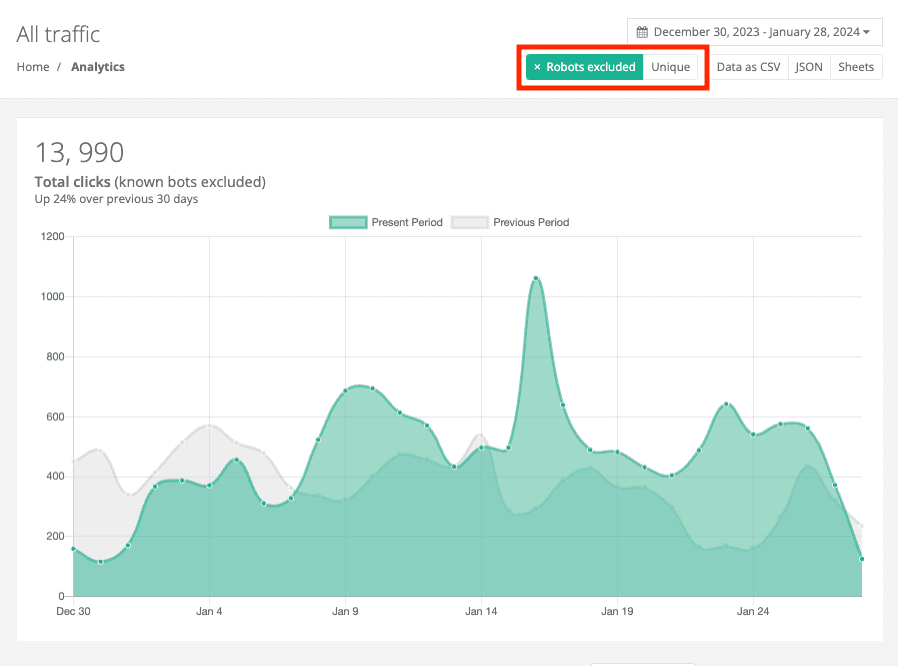
レポートからボットをフィルタリングする方法
トラフィックレポートの右上にあるロボットをフィルターボタンを使用して、分析からボットトラフィックを除外できます。
ボットトラフィックのブロック
オプションとしてボットがあなたのリンクにアクセスするのを完全にブロックできます。ただし、一般的にはこれをお勧めしません理由は以下の通りです:
- スパムをチェックする良いボットがブロックされるとあなたのリンクを疑わしいとフラグを立てる可能性があります
- カスタムソーシャルプレビューはほとんどのプラットフォームで機能しません
- 検索エンジンはあなたのリンクをインデックスできなくなります
ソーシャルメディアプレビューを許可しながら他のボットをブロックするには、あなたのリンクで「ボット&スパイダーをブロック」と「ソーシャルクローラー追跡をスキップ」の両方を有効にしてください。
ボットをブロックする方法
リンクを作成または編集します
ボット&スパイダーをブロックの下で、ロボットをブロックを有効にします

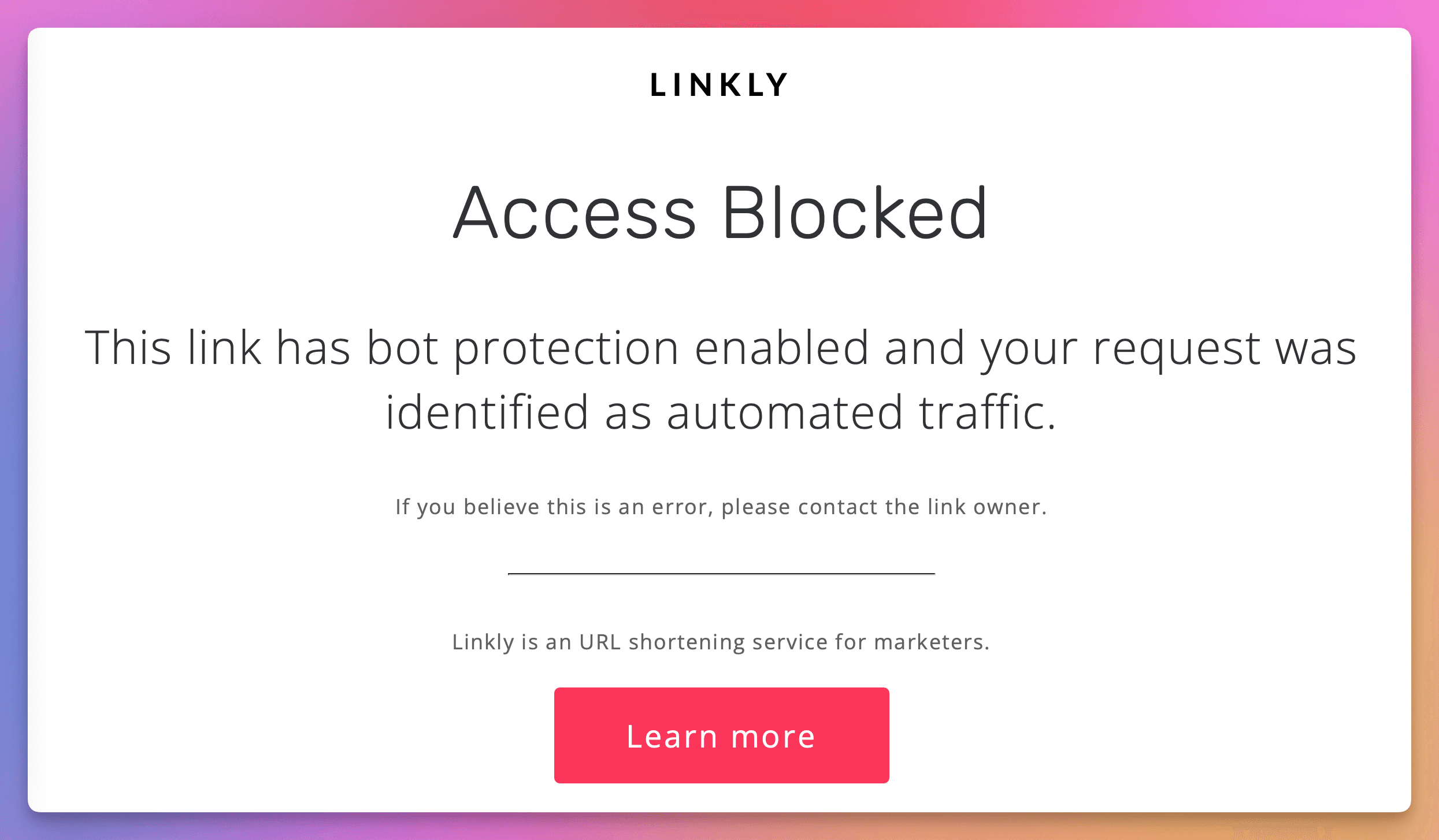
ブロックされたボットはアクセスがブロックされましたページを見ます
返されるHTTPステータスコードは403 Forbiddenです。
よくある質問
なぜ自分のリンクがボットトラフィックを受け取っているのですか?
ボットはプレビューを生成し、スパムをチェックし、検索エンジン用にコンテンツをインデックスするためにリンクを訪問します。これは通常のことで、通常は有益です。
ロボットをブロックすべきですか?
一般的には、いいえ。ロボットをブロックするとあなたのリンクがソーシャルネットワークとメールプロバイダーによってスパムとしてフラグを立てられる可能性があります。
社内リンクなど特定の理由がある場合のみボットをブロックしてください。
なぜほとんどのトラフィックがボットからのものですか?
ソーシャルメディア、メール、またはSMS経由で共有されるリンクは、これらのプラットフォームがスパムとセキュリティの脅威についてリンクを積極的にスキャンするため、かなりのボットトラフィックを生成します。
人間のトラフィックが増えるにつれて、ボットは総クリック数のより小さな割合を占めるようになります。
ボットはクリック制限にカウントされますか?
ほとんどのボットは制限にカウントされます。任意のリクエストを処理するのと同じコストがかかるためです。
ただし、ソーシャルクローラー追跡をスキップを有効にして、Facebook、X、LinkedIn、Google、YouTubeのソーシャルメディアクローラーを制限と分析から除外できます。
ブロックされたリクエストもあなたの制限に対してカウントされません。
なぜGoogle Analyticsでこれらのボットが表示されないのですか?
Google Analyticsはブラウザ JavaScriptに依存して訪問者を追跡します。ボットは通常JavaScriptを実行しないため、GA レポートに表示されません。
Linklyはサーバー側ですべてのトラフィックを記録するため、人間とボットの両方のトラフィックの完全な可視性が得られます。
Linklyは訪問者がボットであることをどのように知るのですか?
ほとんどの正当なボットはユーザーエージェント文字列を通じて自らを識別します。検出されたボットのリストをご覧ください。
自らを識別しないボットについては、リクエストが自動化されたトラフィックを示すクラウドホスティングプロバイダーまたはデータセンターから発生しているかどうかをチェックします。
VPNを使用するとリンクがブロックされるのはなぜですか?
多くのVPNサービスはLinklyがボットの可能性のある源として識別するデータセンターを通じてトラフィックをルーティングします。
別の国からリンクをテストする必要がある場合は、通常の住宅用インターネット接続を持つ誰かにチェックしてもらってください。
広告プラットフォームからの偽クリックはどうですか?
TikTokなどの広告プラットフォームからの無効なトラフィックはボットトラフィックとは異なる問題です。これらのクリックは実際のモバイルデバイスから発生しますが、本物の関心を代表しない可能性があります。
詳細はTikTok無効トラフィックに関する記事をご覧ください。
毎月500クリックを無料で追跡できます。