Robots de recherche
Qu'est-ce qu'un robot de recherche ?
Un robot de recherche, parfois appelé spider, est un robot qui parcourt continuellement Internet, généralement dans le but de créer un index de recherche.
Les bots peuvent gonfler artificiellement les chiffres du trafic, il est donc important d'être conscient de leur existence.
Robots de recherche et Linkly
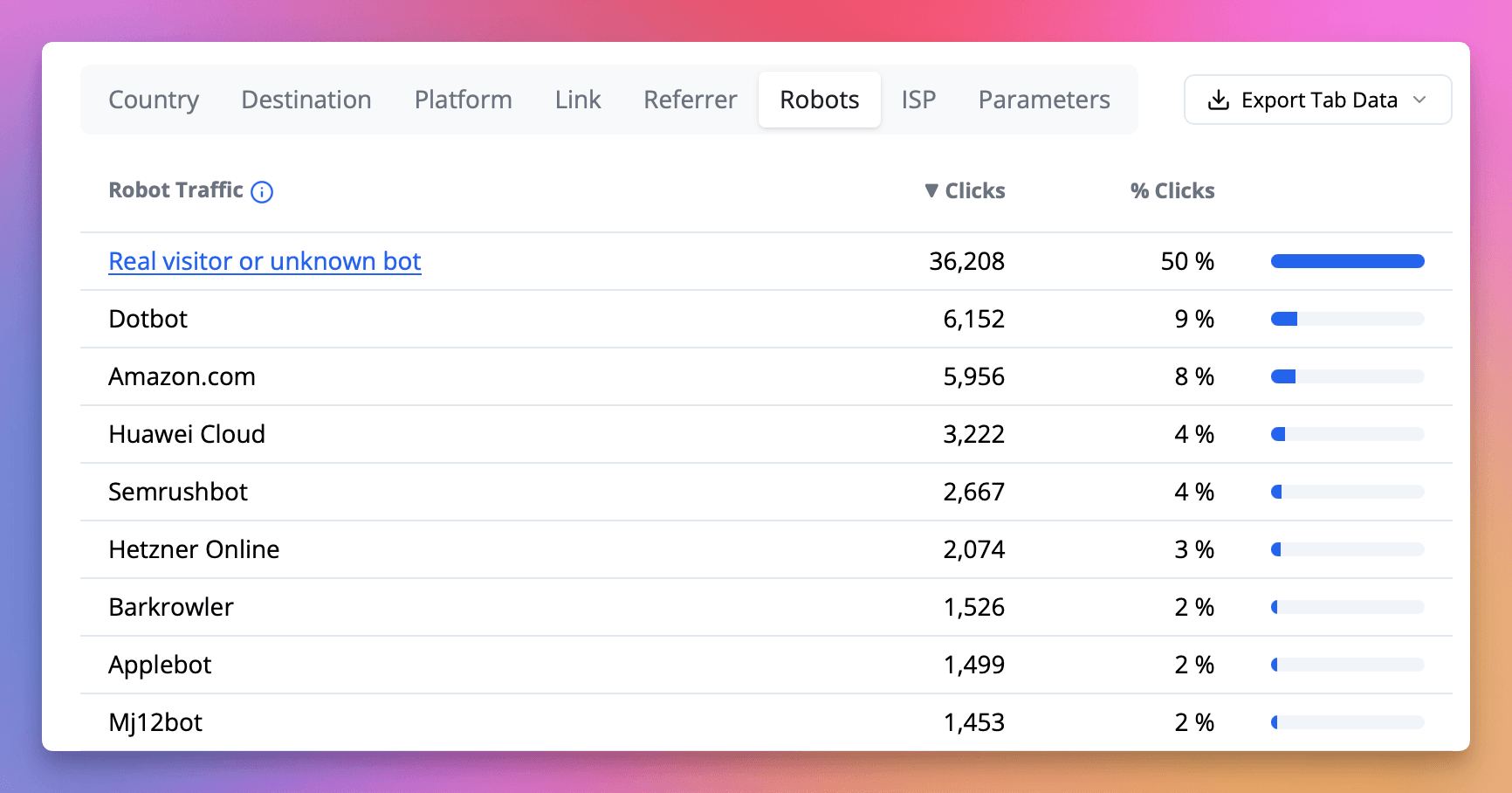
Linkly peut détecter les robots et spiders de recherche qui se révèlent délibérément. Vous pouvez voir quels clics ont été attribués aux bots dans la section Bots du rapport de trafic.
Nous avons un article sur le trafic des bots et comment bloquer les bots.
Traitement spécial pour les crawlers des réseaux sociaux
Linkly a amélioré la gestion des crawlers des réseaux sociaux de Facebook, YouTube, Google, LinkedIn et X.
Lorsque le trafic de ces crawlers accède à vos liens :
-
Il n'est pas enregistré dans vos analyses
-
Il ne compte pas contre vos limites de clics
-
Le crawler est redirigé transparemment vers la bonne destination
-
Ces crawlers sont toujours autorisés à passer, même lorsque la fonction « bloquer les robots » est activée
Cela empêche les crawlers des réseaux sociaux de consommer vos limites de clics tout en leur permettant de générer des aperçus et de vérifier vos liens.
Bloquer les bots pour qu'ils ne suivent pas les liens
Linkly peut bloquer les robots et spiders de recherche pour qu'ils ne suivent pas vos liens. Consultez Trafic des bots pour obtenir des instructions sur l'activation du blocage des bots.
Important : Les crawlers des réseaux sociaux de Facebook, YouTube, Google, LinkedIn et X sont toujours autorisés à passer même lorsque le blocage est activé, afin que les aperçus des liens continuent de fonctionner.
Les bots comptent-ils contre les limites de clics ?
Les crawlers des réseaux sociaux de Facebook, YouTube, Google, LinkedIn et X ne comptent pas contre vos limites de clics et ne sont pas enregistrés dans vos analyses.
Tous les autres bots identifiés ci-dessous comptent contre vos limites de clics, car il en coûte autant pour surveiller et rediriger le trafic, quel que soit la source.
Les bots bloqués (ceux qui rencontrent une page de blocage) ne comptent pas non plus vers vos limites.
Liste des robots de recherche
Voici une liste des robots de recherche et de leurs user-agents que Linkly identifie et qui peuvent être bloqués si nécessaire.
- 200pleasebot 200PleaseBot
- 360spider 360Spider
- abot CrawlDaddy, abot
- addthis AddThis
- adldxbot Microsoft Bing Ads
- admantx ADmantX Platform Semantic Analyzer
- adsbot-google Google Adwords
- advbot AdvBot
- ahrefsbot Ahrefs backlinks research tool
- alexa Alexa Crawler
- apache-httpclient Java http library
- apachebench ApacheBench (ab)
- apis-google APIs-Google
- appengine-google Google App Engine
- applebot Apple Bot
- archive.org_bot Internet Archive (archive.org)
- ask jeeves Ask Jeeves
- asynchttpclient Java http and WebSocket client library
- awe.sm Awe.sm URL expander
- baidu Baidu
- bdcbot Big Data Corp
- bingbot Microsoft Bing
- bingpreview Microsoft Bing preview
- bitlybot bit.ly bot
- blekkobot Blekkobot
- blexbot BLEXBot (webmeup)
- bot@linkfluence.net Linkfluence bot
- bufferbot BufferBot
- buibui-checkbot buibui
- butterfly Topsy Labs
- buzztalk buzztalk
- catchbot CatchBot (catchbot.com)
- check_http Nagios monitor
- cliqzbot Cliqzbot
- cmradar/0.1 CMRadar/0.1
- coldfusion ColdFusion http library
- commoncrawl CCBot
- comodo-webinspector-crawler Comodo
- crowsnest Crowsnest
- curabot cura.yt
- curl curl unix CLI http client
- dap/nethttp DAP/NetHTTP
- datagnionbot datagnion.com/bot.html
- daumoa Korean portal and search engine indexing bot
- developers.google.com/+/web/snippet/ Google Plus
- diffbot Diffbot
- digitalpersona fingerprint software HP Fingerprint scanner
- domain re-animator bot Domain Re-Animator Bot
- domainsbot DomainsBot
- domaintunocrawler DomainTuno
- dotbot Dot Bot
- duckduck Duck Duck Go
- elb-healthchecker AWS ELB HealthChecker
- embedly Embedly
- eoaagent EOAAgent
- eventmachine httpclient Ruby http library
- everyonesocialbot EveryoneSocial
- evrinid Evri bot
- exabot Exalead's bot
- exaleadcloudview ExaleadCloudView
- facebookexternalhit Facebook Bot
- facebot Facebook Bot
- feedburner RSS bot
- feedfetcher-google Google Feedfetcher
- findxbot Findxbot
- flipboardproxy FlipboardProxy
- friendfeedbot FriendFeed
- genieo Genieo Web filter bot
- getprismatic.com getprismatic.com
- gigabot Gigabot spider
- gimme60bot Gimme60 (gimme60.com)
- gimmeusabot Gimme60 (gimme60.com)
- go http package Go http library
- google page speed insights Google Page Speed Insights
- google Web Preview Google Instant Previews crawler
- google-structured-data-testing-tool Google-StructuredDataTestingTool
- google-structureddatatestingtool Google-StructuredDataTestingTool
- googlebot Google Bot
- googlestackdrivermonitoring-uptimechecks GoogleStackdriverMonitoring-UptimeChecks
- grapeshotcrawler GrapeshotCrawler
- gravitybot Gravity Bot
- hatena::bookmark Hatena::Bookmark
- heritrix heritrix
- htmlparser HTMLParser
- http_request2 HTTP_Request2
- httpclient HTTPClient
- https://developers.google.com/+/web/snippet Google+ Snippet Fetcher
- hubspot HubSpot
- ia_archiver Internet Archive (WayBackMachine)
- icoreservice iCoreService
- idmarch idmarch.org/bot.html
- inagist URL resolver
- insieve Insieve Bot
- insitesbot Insitesbot
- instapaper Instapaper
- istellabot IstellaBot
- jack jack
- jakarta commons Jakarta Commons HttpClient
- java Generic Java http library
- jetslide Jetslide
- js-kit URL resolver
- kemvibot Kemvi
- kimengi Kimengi Bot
- knows.is knows.is
- kojitsubot Kojitsubot
- komodiabot KomodiaBot
- kraken kraken
- laconica Laconica
- libwww-perl Perl client-server library
- lijit crawler Lijit
- linkdexbot Linkdex Bot
- linkedinbot LinkedIn
- linkscrawler LinksCrawler
- linode Linode Longview
- lipperhey Lipperhey
- livelapbot Livelapbot
- loadtimebot Load Time Bot
- longurl URL expander service
- ltx71 ltx71.com
- lumibot Lumibot
- lwp-trivial Another Perl library
- magpie-crawler magpie-crawler
- mail.ru_bot Mail.ru Bot
- meanpathbot meanpath
- mediapartners-google Google Adsense bot
- megaindex.ru MegaIndex
- memorybot mignify.com/bot.html
- metauri MetaURI
- mfe_expand Mcafee spider
- mir web crawler MIR web crawler
- mj12bot Majestic-12 spider
- mojeekbot Mojeek UK search crawler
- mrchrome MrChrome
- ms search 6.0 robot MS Search 6.0 Robot
- msnbot-media Microsoft media bot
- msnbot Microsoft bot
- nerdybot NerdyBot
- netcraft Netcraft
- netstate netEstate NE Crawler
- netvibes Personalized dashboard bot
- netzcheckbot netzcheck
- newrelicmonitor NewRelic monitor
- newrelicpinger NewRelicPinger
- newsme newsme
- niki-bot niki-bot
- ning NING - Yet Another Twitter Swarmer
- nutch Apache search spider
- openhosebot OpenHoseBot
- orangebot OrangeBot
- pagesinventory pagesinventory.com
- panopta Monitoring service
- paperlibot PaperLi
- peerindex peerindex
- percolatecrawler PercolateCrawler
- perfectmarketkwtbot PerfectMarket
- phantomjs PhantomJS
- pingdom Pingdom monitoring
- pinterest Pinterest
- plukkie botje.com/plukkie.htm
- privacyawarebot PrivacyAwareBot
- proximic Proximic Spider
- psbot-page Picsearch
- publiclibraryarchive.org publiclibraryarchive.org
- pycurl Python http library
- python-httplib2 Python-httplib2
- python-requests Python http library
- python-urllib Python http library
- queryseeker QuerySeekerSpider
- quicklook QuickLook
- re-animator Domain Re-Animator Bot
- readability Readability
- rebelmouse RebelMouse
- redditbot Reddit Bot
- relateiq RelateIQ
- riddler Riddler Bot
- rogerbot SeoMoz spider
- rssmicro RSS/Atom Feed Robot (rssmicro.com)
- ruby Ruby
- scrapy Scrapy
- screaming frog seo spider Screaming Frog SEO Spider
- searchmetricsbot SearchmetricsBot
- semrushbot SEO analysis bot
- seokicks SEOKicks
- seznambot SeznamBot
- shopwiki ShopWiki
- shortlinktranslate Link shortener
- showyoubot Showyou iOS app spider
- siege Joe Dog Siege
- sistrix SISTRIX
- siteuptime Site monitoring services
- slack Slackbot-LinkExpanding
- slackbot Slack Bot
- slurp Yahoo spider
- smtbot SimilarTech
- socialrank SocialRankIOBot
- sogou Chinese search engine
- spbot OpenLinkProfiler
- spider generic web spider
- spinn3r Spinn3r aggregator
- sputnikbot SputnikBot
- squider Squider
- statuscake StatusCake
- stripe Stripe
- test certificate info C http library?
- tineye TinEye Bot
- traackr Traackr Bot
- trendictionbot Trendiction Search
- turnitinbot TurnitinBot
- tweetedtimes The Tweeted Times
- tweetmemebot TweetMeMe Crawler
- twikle Social web search bot
- twitjobsearch TwitJobSearch
- twitmunin Twitmunin
- twitterbot Twitter URL expander
- twurly Twurly
- typhoeus Typhoeus
- umbot uberMetrics
- unwindfetch Gnip
- uptimerobot Uptime Robot
- vagabondo Vagabondo
- vb project Visual Basic
- vigil Vigil
- vkshare VKontake Sharer
- voilabot VoilaBot
- vrcrawler Venture Radar
- wasalive-bot Wasalive Bots
- watchsumo WatchSumo
- wbsearchbot Ware Bay Best Buys
- webscout Webscout
- wesee WeSEE
- wget wget unix CLI http client
- wordpress WordPress spider
- wormly WormlyBot
- wotbox Wotbox
- xenu link sleuth Xenu Link Sleuth
- xing-contenttabreceiver Xing bot
- xovibot XoviBot
- yacybot YaCy
- yahoo-ad-monitoring Yahoo Ad monitoring
- yandex Yandex
- yeti Naver Corp
- yourls YOURLS
- zelist.ro feed parser
- zibb ZIBB spider
- zitebot Zite
- zyborg Zyborg
Fournisseurs de cloud identifiés comme des bots
De nombreux bots ne s'identifient pas comme tels, mais nous suivons les fournisseurs de services Internet et identifions le trafic en provenance des principaux fournisseurs de cloud comme étant probablement des bots.
- Google Cloud
- Microsoft Corporation
- OVH SAS
- DigitalOcean
- Huawei Clouds
- Google-private-cloud
- Amazon.com
- Google Proxy
- Omonia d.o.o.
- ColoCrossing
FAQ sur les robots de recherche
Comment Linkly détecte-t-il les bots ?
Linkly identifie les bots par leur chaîne user agent (de nombreux bots se déclarent eux-mêmes) et en vérifiant si le trafic provient de fournisseurs d'hébergement en nuage connus ou de centres de données.
Un bot manque-t-il de cette liste ?
Nous mettrons à jour régulièrement notre détection de bots. Si vous voyez du trafic provenant d'un bot ne figurant pas sur cette liste, contactez-nous et nous l'ajouterons.
Pourquoi certains clics sont-ils marqués comme des bots alors qu'il s'agit d'utilisateurs réels ?
Les utilisateurs sur des VPN ou des réseaux d'entreprise peuvent être signalés comme des bots car leur trafic est acheminé via des centres de données. Consultez notre article sur le trafic VPN pour plus d'informations.
Obtenez 100 liens courts et suivez 500 clics mensuels gratuitement.